接上一篇文章 Spring 使用简单Demo进行源码调试(一)
在运行到下面语句
该构造函数首先进入下面ClassPathXmlApplicationContext类中这段代码。代码中configLocations为我们的配置文件,及[bean.xml];refresh表示是否刷新,这里为true,表示刷新配置;parent表示上级上下文,这里为null表示没有上级上下文。
接上一篇文章 Spring 使用简单Demo进行源码调试(一)
在运行到下面语句
该构造函数首先进入下面ClassPathXmlApplicationContext类中这段代码。代码中configLocations为我们的配置文件,及[bean.xml];refresh表示是否刷新,这里为true,表示刷新配置;parent表示上级上下文,这里为null表示没有上级上下文。
第一步
在源码调试之前,需要将spring源码进行编译,这里选择的是3.2.x版本,这个版本在导入eclipse都会出现bug,但是不影响目前的调试。
第二步
将编译后的源码导入eclispe,如下图所示: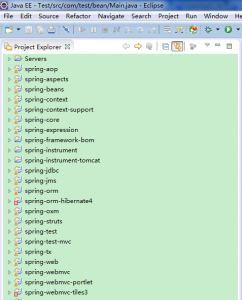
可以看到有两个工程报错,分别是spring—orm-hibernate4和spring-webmvc-tiles3,暂且不去管它,因为目前不会影响到后续的源码调试。
第三步
新建一个工程,Test,然后右键该工程,选择Build path -》 Configure Build Path…,然后把当前所有的没有报错的工程加入到Projects里,如下图所示: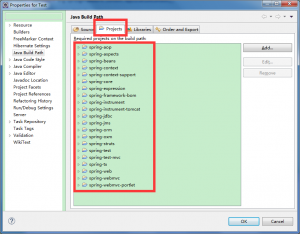
1.java实现文件复制、剪切文件和删除
[java]
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
public class FileOperateDemo {
/**
* 复制文件或文件夹
* @param srcPath 源文件或源文件夹的路径
* @param destDir 目标文件所在的目录
* @return
*/
public static boolean copyGeneralFile(String srcPath, String destDir) {
boolean flag = false;
File file = new File(srcPath);
if(!file.exists()) { // 源文件或源文件夹不存在
return false;
}
if(file.isFile()) { // 文件复制
flag = copyFile(srcPath, destDir);
}
else if(file.isDirectory()) { // 文件夹复制
flag = copyDirectory(srcPath, destDir);
}
return flag;
}
/**
* 默认的复制文件方法,默认会覆盖目标文件夹下的同名文件
* @param srcPath
* 源文件绝对路径
* @param destDir
* 目标文件所在目录
* @return boolean
*/
public static boolean copyFile(String srcPath, String destDir) {
return copyFile(srcPath, destDir, true/**overwriteExistFile*/); // 默认覆盖同名文件
}
/**
* 默认的复制文件夹方法,默认会覆盖目标文件夹下的同名文件夹
* @param srcPath 源文件夹路径
* @param destPath 目标文件夹所在目录
* @return boolean
*/
public static boolean copyDirectory(String srcPath, String destDir) {
return copyDirectory(srcPath, destDir, true/**overwriteExistDir*/);
}
/**
* 复制文件到目标目录
* @param srcPath
* 源文件绝对路径
* @param destDir
* 目标文件所在目录
* @param overwriteExistFile
* 是否覆盖目标目录下的同名文件
* @return boolean
*/
public static boolean copyFile(String srcPath, String destDir, boolean overwriteExistFile) {
boolean flag = false;
File srcFile = new File(srcPath);
if (!srcFile.exists() || !srcFile.isFile()) { // 源文件不存在
return false;
}
//获取待复制文件的文件名
String fileName = srcFile.getName();
String destPath = destDir + File.separator +fileName;
File destFile = new File(destPath);
if (destFile.getAbsolutePath().equals(srcFile.getAbsolutePath())) { // 源文件路径和目标文件路径重复
return false;
}
if(destFile.exists() && !overwriteExistFile) { // 目标目录下已有同名文件且不允许覆盖
return false;
}
File destFileDir = new File(destDir);
if(!destFileDir.exists() && !destFileDir.mkdirs()) { // 目录不存在并且创建目录失败直接返回
return false;
}
try {
FileInputStream fis = new FileInputStream(srcPath);
FileOutputStream fos = new FileOutputStream(destFile);
byte[] buf = new byte[1024];
int c;
while ((c = fis.read(buf)) != -1) {
fos.write(buf, 0, c);
}
fos.flush();
fis.close();
fos.close();
flag = true;
} catch (IOException e) {
e.printStackTrace();
}
return flag;
}
/**
*
* @param srcPath 源文件夹路径
* @param destPath 目标文件夹所在目录
* @return
*/
public static boolean copyDirectory(String srcPath, String destDir, boolean overwriteExistDir) {
if(destDir.contains(srcPath))
return false;
boolean flag = false;
File srcFile = new File(srcPath);
if (!srcFile.exists() || !srcFile.isDirectory()) { // 源文件夹不存在
return false;
}
//获得待复制的文件夹的名字,比如待复制的文件夹为"E:\\dir\\"则获取的名字为"dir"
String dirName = srcFile.getName();
//目标文件夹的完整路径
String destDirPath = destDir + File.separator + dirName + File.separator;
File destDirFile = new File(destDirPath);
if(destDirFile.getAbsolutePath().equals(srcFile.getAbsolutePath())) {
return false;
}
if(destDirFile.exists() && destDirFile.isDirectory() && !overwriteExistDir) { // 目标位置有一个同名文件夹且不允许覆盖同名文件夹,则直接返回false
return false;
}
if(!destDirFile.exists() && !destDirFile.mkdirs()) { // 如果目标目录不存在并且创建目录失败
return false;
}
File[] fileList = srcFile.listFiles(); //获取源文件夹下的子文件和子文件夹
if(fileList.length==0) { // 如果源文件夹为空目录则直接设置flag为true,这一步非常隐蔽,debug了很久
flag = true;
}
else {
for(File temp: fileList) {
if(temp.isFile()) { // 文件
flag = copyFile(temp.getAbsolutePath(), destDirPath, overwriteExistDir); // 递归复制时也继承覆盖属性
}
else if(temp.isDirectory()) { // 文件夹
flag = copyDirectory(temp.getAbsolutePath(), destDirPath, overwriteExistDir); // 递归复制时也继承覆盖属性
}
if(!flag) {
break;
}
}
}
return flag;
}
/**
* 删除文件或文件夹
* @param path
* 待删除的文件的绝对路径
* @return boolean
*/
public static boolean deleteFile(String path) {
boolean flag = false;
File file = new File(path);
if (!file.exists()) { // 文件不存在直接返回
return flag;
}
flag = file.delete();
return flag;
}
/**
* 由上面方法延伸出剪切方法:复制+删除
* @param destDir 同上
*/
public static boolean cutGeneralFile(String srcPath, String destDir) {
boolean flag = false;
if(copyGeneralFile(srcPath, destDir) && deleteFile(srcPath)) { // 复制和删除都成功
flag = true;
}
return flag;
}
public static void main(String[] args) {
/** 测试复制文件 */
System.out.println(copyGeneralFile("d://test/test.html", "d://test/test/")); // 一般正常场景
System.out.println(copyGeneralFile("d://notexistfile", "d://test/")); // 复制不存在的文件或文件夹
System.out.println(copyGeneralFile("d://test/test.html", "d://test/")); // 待复制文件与目标文件在同一目录下
System.out.println(copyGeneralFile("d://test/test.html", "d://test/test/")); // 覆盖目标目录下的同名文件
System.out.println(copyFile("d://test/", "d://test2", false)); // 不覆盖目标目录下的同名文件
System.out.println(copyGeneralFile("d://test/test.html", "notexist://noexistdir/")); // 复制文件到一个不可能存在也不可能创建的目录下
System.out.println("---------");
/** 测试复制文件夹 */
System.out.println(copyGeneralFile("d://test/", "d://test2/"));
System.out.println("---------");
/** 测试删除文件 */
System.out.println(deleteFile("d://a/"));
}
}
[/java]
2.验证传入路径是否为正确的路径名(Windows系统,其他系统未使用)
[java]
// 验证字符串是否为正确路径名的正则表达式
private static String matches = "[A-Za-z]:\\[^:?\"><]";
// 通过 sPath.matches(matches) 方法的返回值判断是否正确
// sPath 为路径字符串
[/java]
3.通用的文件夹或文件删除方法,直接调用此方法,即可实现删除文件夹或文件,包括文件夹下的所有文件
[java]
/**
return flag;
// 判断是否为文件
if (file.isFile()) { // 为文件时调用删除文件方法
return deleteFile(sPath);
} else { // 为目录时调用删除目录方法
return deleteDirectory(sPath);
}
4.实现删除文件的方法,
[java]
/**
file.delete();
flag = true;
5.实现删除文件夹的方法,
[java]
/**
sPath = sPath + File.separator;
return false;
//删除子文件
if (files[i].isFile()) {
flag = deleteFile(files[i].getAbsolutePath());
if (!flag) break;
} //删除子目录
else {
flag = deleteDirectory(files[i].getAbsolutePath());
if (!flag) break;
}
return true;
return false;
Mysql自5.1开始对分区(Partition)有支持
= 水平分区(根据列属性按行分)=
举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录。
=== 水平分区的几种模式:===
Range(范围) – 这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过年份划分成三个分区,80年代(1980’s)的数据,90年代(1990’s)的数据以及任何在2000年(包括2000年)后的数据。
Hash(哈希) – 这中模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,。例如DBA可以建立一个对表主键进行分区的表。
Key(键值) – 上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
List(预定义列表) – 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据。
Composite(复合模式) - 很神秘吧,哈哈,其实是以上模式的组合使用而已,就不解释了。举例:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
= 垂直分区(按列分)=
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
[分区表和未分区表试验过程]
*创建分区表,按日期的年份拆分
[sql]
CREATE TABLE part_tab ( c1 int default NULL, c2 varchar(30) default NULL, c3 date default NULL) engine=myisam
PARTITION BY RANGE (year(c3)) (PARTITION p0 VALUES LESS THAN (1995),
PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) ,
PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) ,
PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) ,
PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010),
PARTITION p11 VALUES LESS THAN MAXVALUE ); [/sql]
注意最后一行,考虑到可能的最大值
*创建未分区表
[sql]
mysql> create table no_part_tab (c1 int(11) default NULL,c2 varchar(30) default NULL,c3 date default NULL) engine=myisam;
[/sql]
通过存储过程灌入800万条测试数据
mysql> set sql_mode=’’; / 如果创建存储过程失败,则先需设置此变量, bug? /
mysql> delimiter // / 设定语句终结符为 //,因存储过程语句用;结束 */
[sql]
mysql> CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,’testing partitions’,adddate(‘1995-01-01’,(rand(v)36520) mod 3652));
set v = v + 1;
end while;
end
//
mysql> delimiter ;
mysql> call load_part_tab();
Query OK, 1 row affected (8 min 17.75 sec)
[sql] view plaincopy
mysql> insert into no_part_tab select from part_tab;
Query OK, 8000000 rows affected (51.59 sec)
Records: 8000000 Duplicates: 0 Warnings: 0
[/sql]
[sql]
mysql> select count() from part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1995-12-31’;
+———-+
| count() |
+———-+
| 795181 |
+———-+
1 row in set (0.55 sec)
[/sql]
[sql]
mysql> select count() from no_part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1995-12-31’;
+———-+
| count() |
+———-+
| 795181 |
+———-+
1 row in set (4.69 sec)[/sql]
结果表明分区表比未分区表的执行时间少90%。
id: 1
table: no_part_tab
type: ALL
key: NULL
key_len: NULL
ref: NULL
rows: 8000000
Extra: Using where
[sql]
mysql> explain select count() from part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1995-12-31’\G
** 1. row *
id: 1
select_type: SIMPLE
table: part_tab
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 798458
Extra: Using where
1 row in set (0.00 sec)[/sql]
explain语句显示了SQL查询要处理的记录数目
试验创建索引后情况
[sql]
mysql> create index idx_of_c3 on no_part_tab (c3);
Query OK, 8000000 rows affected (1 min 18.08 sec)
Records: 8000000 Duplicates: 0 Warnings: 0
[/sql]
[sql]
mysql> create index idx_of_c3 on part_tab (c3);
Query OK, 8000000 rows affected (1 min 19.19 sec)
Records: 8000000 Duplicates: 0 Warnings: 0[/sql]
创建索引后的数据库文件大小列表:
2008-05-24 09:23 8,608 no_part_tab.frm
2008-05-24 09:24 255,999,996 no_part_tab.MYD
2008-05-24 09:24 81,611,776 no_part_tab.MYI
2008-05-24 09:25 0 part_tab#P#p0.MYD
2008-05-24 09:26 1,024 part_tab#P#p0.MYI
2008-05-24 09:26 25,550,656 part_tab#P#p1.MYD
2008-05-24 09:26 8,148,992 part_tab#P#p1.MYI
2008-05-24 09:26 25,620,192 part_tab#P#p10.MYD
2008-05-24 09:26 8,170,496 part_tab#P#p10.MYI
2008-05-24 09:25 0 part_tab#P#p11.MYD
2008-05-24 09:26 1,024 part_tab#P#p11.MYI
2008-05-24 09:26 25,656,512 part_tab#P#p2.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p2.MYI
2008-05-24 09:26 25,586,880 part_tab#P#p3.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p3.MYI
2008-05-24 09:26 25,585,696 part_tab#P#p4.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p4.MYI
2008-05-24 09:26 25,585,216 part_tab#P#p5.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p5.MYI
2008-05-24 09:26 25,655,740 part_tab#P#p6.MYD
2008-05-24 09:26 8,181,760 part_tab#P#p6.MYI
2008-05-24 09:26 25,586,528 part_tab#P#p7.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p7.MYI
2008-05-24 09:26 25,586,752 part_tab#P#p8.MYD
2008-05-24 09:26 8,160,256 part_tab#P#p8.MYI
2008-05-24 09:26 25,585,824 part_tab#P#p9.MYD
2008-05-24 09:26 8,159,232 part_tab#P#p9.MYI
2008-05-24 09:25 8,608 part_tab.frm
2008-05-24 09:25 68 part_tab.par
再次测试SQL性能
[sql]
mysql> select count() from no_part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1995-12-31’;
+———-+
| count() |
+———-+
| 795181 |
+———-+
1 row in set (2.42 sec) / 为原来4.69 sec 的51%/
[/sql]
重启mysql ( net stop mysql, net start mysql)后,查询时间降为0.89 sec,几乎与分区表相同。
[sql]
mysql> select count() from part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1995-12-31’;
+———-+
| count() |
+———-+
| 795181 |
+———-+
1 row in set (0.86 sec)
[/sql]
* 增加未索引字段查询
[sql]
mysql> select count() from part_tab where c3 > date ‘1995-01-01’ and c3 < date
‘1996-12-31’ and c2=’hello’;
+———-+
| count() |
+———-+
| 0 |
+———-+
1 row in set (0.75 sec)
[/sql]
[sql]
mysql> select count() from no_part_tab where c3 > date ‘1995-01-01’ and c3 < date ‘1996-12-31’ and c2=’hello’;
+———-+
| count(*) |
+———-+
| 0 |
+———-+
1 row in set (11.52 sec)
[/sql]
= 初步结论 =
= 最终结论 =
[分区命令详解]
= 分区例子 =
RANGE 类型
[sql]
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) (
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES LESS THAN (9000000)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES LESS THAN MAXVALUE DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
); [/sql]
在这里,将用户表分成4个分区,以每300万条记录为界限,每个分区都有自己独立的数据、索引文件的存放目录,与此同时,这些目录所在的物理磁盘分区可能也都是完全独立的,可以提高磁盘IO吞吐量。
LIST 类型
[sql]
CREATE TABLE category (
cid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ‘’
)
PARTITION BY LIST (cid) (
PARTITION p0 VALUES IN (0,4,8,12)
DATA DIRECTORY = ‘/data0/data’
INDEX DIRECTORY = ‘/data1/idx’,
PARTITION p1 VALUES IN (1,5,9,13)
DATA DIRECTORY = ‘/data2/data’
INDEX DIRECTORY = ‘/data3/idx’,
PARTITION p2 VALUES IN (2,6,10,14)
DATA DIRECTORY = ‘/data4/data’
INDEX DIRECTORY = ‘/data5/idx’,
PARTITION p3 VALUES IN (3,7,11,15)
DATA DIRECTORY = ‘/data6/data’
INDEX DIRECTORY = ‘/data7/idx’
); [/sql]
分成4个区,数据文件和索引文件单独存放。
HASH 类型
[sql]
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ‘’,
email VARCHAR(30) NOT NULL DEFAULT ‘’
)
PARTITION BY HASH (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = ‘/data0/data’
INDEX DIRECTORY = ‘/data1/idx’,
PARTITION p1
DATA DIRECTORY = ‘/data2/data’
INDEX DIRECTORY = ‘/data3/idx’,
PARTITION p2
DATA DIRECTORY = ‘/data4/data’
INDEX DIRECTORY = ‘/data5/idx’,
PARTITION p3
DATA DIRECTORY = ‘/data6/data’
INDEX DIRECTORY = ‘/data7/idx’
); [/sql]
分成4个区,数据文件和索引文件单独存放。
例子:
[sql]
CREATE TABLE ti2 (id INT, amount DECIMAL(7,2), tr_date DATE)
ENGINE=myisam
PARTITION BY HASH( MONTH(tr_date) )
PARTITIONS 6;
CREATE PROCEDURE load_ti2()
begin
declare v int default 0;
while v < 80000
do
insert into ti2
values (v,’3.14’,adddate(‘1995-01-01’,(rand(v)*3652) mod 365));
set v = v + 1;
end while;
end
//
[/sql]
KEY 类型
[sql]
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ‘’,
email VARCHAR(30) NOT NULL DEFAULT ‘’
)
PARTITION BY KEY (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = ‘/data0/data’
INDEX DIRECTORY = ‘/data1/idx’,
PARTITION p1
DATA DIRECTORY = ‘/data2/data’
INDEX DIRECTORY = ‘/data3/idx’,
PARTITION p2
DATA DIRECTORY = ‘/data4/data’
INDEX DIRECTORY = ‘/data5/idx’,
PARTITION p3
DATA DIRECTORY = ‘/data6/data’
INDEX DIRECTORY = ‘/data7/idx’
); [/sql]
分成4个区,数据文件和索引文件单独存放。
子分区
子分区是针对 RANGE/LIST 类型的分区表中每个分区的再次分割。再次分割可以是 HASH/KEY 等类型。例如:
[sql]
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ‘’,
email VARCHAR(30) NOT NULL DEFAULT ‘’
)
PARTITION BY RANGE (uid) SUBPARTITION BY HASH (uid % 4) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = ‘/data0/data’
INDEX DIRECTORY = ‘/data1/idx’,
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = ‘/data2/data’
INDEX DIRECTORY = ‘/data3/idx’
); [/sql]
对 RANGE 分区再次进行子分区划分,子分区采用 HASH 类型。
或者
[sql]
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ‘’,
email VARCHAR(30) NOT NULL DEFAULT ‘’
)
PARTITION BY RANGE (uid) SUBPARTITION BY KEY(uid) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = ‘/data0/data’
INDEX DIRECTORY = ‘/data1/idx’,
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = ‘/data2/data’
INDEX DIRECTORY = ‘/data3/idx’
); [/sql]
对 RANGE 分区再次进行子分区划分,子分区采用 KEY 类型。
= 分区管理 =
* 删除分区
[sql]
ALERT TABLE users DROP PARTITION p0; [/sql]
删除分区 p0。
* 重建分区
o RANGE 分区重建
[sql]
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES LESS THAN (6000000)); [/sql]
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
o LIST 分区重建
[sql]
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES IN(0,1,4,5,8,9,12,13)); [/sql]
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
o HASH/KEY 分区重建
[sql]
ALTER TABLE users REORGANIZE PARTITION COALESCE PARTITION 2; [/sql]
用 REORGANIZE 方式重建分区的数量变成2,在这里数量只能减少不能增加。想要增加可以用 ADD PARTITION 方法。
* 新增分区
o 新增 RANGE 分区
[sql]
ALTER TABLE category ADD PARTITION (PARTITION p4 VALUES IN (16,17,18,19)
DATA DIRECTORY = ‘/data8/data’
INDEX DIRECTORY = ‘/data9/idx’); [/sql]
新增一个RANGE分区。
o 新增 HASH/KEY 分区
[sql]
ALTER TABLE users ADD PARTITION PARTITIONS 8; [/sql]
将分区总数扩展到8个。
[ 给已有的表加上分区 ]
[sql]
alter table results partition by RANGE (month(ttime))
(PARTITION p0 VALUES LESS THAN (1),
PARTITION p1 VALUES LESS THAN (2) , PARTITION p2 VALUES LESS THAN (3) ,
PARTITION p3 VALUES LESS THAN (4) , PARTITION p4 VALUES LESS THAN (5) ,
PARTITION p5 VALUES LESS THAN (6) , PARTITION p6 VALUES LESS THAN (7) ,
PARTITION p7 VALUES LESS THAN (8) , PARTITION p8 VALUES LESS THAN (9) ,
PARTITION p9 VALUES LESS THAN (10) , PARTITION p10 VALUES LESS THAN (11),
PARTITION p11 VALUES LESS THAN (12),
PARTITION P12 VALUES LESS THAN (13) ); [/sql]
默认分区限制分区字段必须是主键(PRIMARY KEY)的一部分,为了去除此
限制:
[方法1] 使用ID
[sql]
mysql> ALTER TABLE np_pk
-> PARTITION BY HASH( TO_DAYS(added) )
-> PARTITIONS 4;
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table’s partitioning function
[/sql]
However, this statement using the id column for the partitioning column is valid, as shown here:
[sql]
mysql> ALTER TABLE np_pk
-> PARTITION BY HASH(id)
-> PARTITIONS 4;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
[/sql]
[方法2] 将原有PK去掉生成新PK
[sql]
mysql> alter table results drop PRIMARY KEY;
Query OK, 5374850 rows affected (7 min 4.05 sec)
Records: 5374850 Duplicates: 0 Warnings: 0
[/sql]
[sql]
mysql> alter table results add PRIMARY KEY(id, ttime);
Query OK, 5374850 rows affected (6 min 14.86 sec)
Records: 5374850 Duplicates: 0 Warnings: 0
[/sql]
1. linux文件系统都有三个身份Owner, group, others, 每种身份都有r,w,x三种权限。
2. /etc/passwd 存有系统的用户信息,/etc/shadow存有用户的密码,/etc/group 存有组的情况。
3. 更改权限的三个命令:chmod, chgrp, chown
对于文件来说:r–读取文件内容;w–编辑、新增文件(不可删除);x-可执行
umask 决定新建文件或文件夹的权限,显示的值为需要去掉的权限
对于目录来说:r–使用ls查看目录文件;w–创建、删除、移动、重命名文件;x-可使用cd切换目录
4. /sbin/service, /sbin/ifconfig默认状况下只有root用户才能直接使用
5.路径:. , .. ,~
6. 目录有关的操作:cd,pwd,mkdir, rmdir
7.文件操作:ls,cp,rm,mv,touch
8.文件查阅:cat/tac, nl,more,less。head,tail
9.查看文件类型:file
10.查找脚本:which 查找文件名: whereis, locate, find
find -name -type -user -exec ls {} \;
11. 添加用户useradd;用户组groupadd
用户查询:w/who 用户通讯:mesg,write,wall
批量添加用户和密码:useradd user;echo user | passwd –stdin user
12. 磁盘有关命令:df/du 查看磁盘; fdisk -l查看磁盘分区;fsck系统检查;mount挂载磁盘,新建目录,挂载磁盘分区;umount卸载磁盘
13. 打包 tar -czvf, 解压tar -xzvf
14.Vim编辑器使用
15.正则表达式和grep
16. awk,sed
17. Shell脚本
18.程序管理:
查看 进程 ps -ef | grep pname ps aux
后台运行&
后台暂停:ctr+z
查看后台进程: jobs -l
恢复前台 fg %jobnumber
后台运行:bg %jobnumber
脱机运行:nohup
查看动态进程:top
强制杀死进程:kill -9 pid
19. 查看内存: free -m;查看内核:uname -a;跟踪网络 netstat -a -tlnp
20. /etc/init.d/ 系统启动脚本
/etc/ 系统配置
/var/lib/* 各服务产生的数据库
service name start/stop/restart/status
chkconfig –list –add 开机启动 防火墙 iptables
/var/log 系统日志文件
21. 软件安装:rqm -ivh | -aq| -e ;yum install
1. cd to the root directory of your code:
2.Run Ctags recursively over the entire code to generate the tags file
ctags -R *
3. To search for a specific tag and open Vim to its definition, run the following command in your shell:
vim -t
4. Or, open any Linux source file in Vim and use the following basic commands:
Ctrl-] Jump to the tag underneath the cursor
:ts
:tn Go to the next definition for the last tag
:tp Go to the previous definition for the last tag
:ts List all of the definitions of the last tag
Ctrl-t Jump back up in the tag stack
The first command is probably the one you will use most often: it jumps to the definition of the tag (function name, structure name, variable name, or pretty much anything) under the cursor. The second command can be used to search for any tag, regardless of the file that is currently opened. If there are multiple definitions/uses for a particular tag, the tn and tp commands can be used to scroll through them, and the ts command can be used to “search” a list for the definition you want (useful when there are dozens or hundreds of definitions for some commonly-used struct). Finally, the last command is used to jump back up in the tag stack to the location you initiated the previous tag search from.
1. Install prerequisites on server node
Step 0: Use yum to install dependency
Step 1: Install libconfuse
Step 2: Install rrdtool on server node
Step 3(Optional): Install libpre
2. Install and configure gmetad&gmond on server node
Step 0: Install ganglia code
Ganglia can not be compiled successfully until the information as below shows up.
Welcome to..
______ ___
/ ____/___ _____ ____ _/ (_)___ _
/ / / / __ \/ __/ / / `/
/ // / // / / / / // / / / // /
__/_,// //_, ///__,/
/__/
Copyright (c) 2005 University of California, Berkeley
Step 1: Check gmetad&gmond binary
/usr/local/bin/gmetric
/usr/local/sbin/gmond
/usr/local/sbin/gmetad
Step 2: Customize data_source name and hosts in gmetad.conf
data_source “cluster1” mdw # provide the name of host containing all data, better more than one if a cluster, default port number is 8649
Step 3: Generate && Customize gmond.conf(Using unicast)
At this point you may get this error
gmond: error while loading shared libraries: libpcre.so.1: cannot open shared object file: No such file or directory
Create a symlink and execute the command again
cluster {
name = “cluster1” # use the cluster name defined in gmetad.conf
owner = “unspecified”
latlong = “unspecified”
url = “unspecified”
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
host = 172.28.8.250 #if using unicast, provide ip address of server node, host and mcast_join cannot be in a channel
port = 8649
ttl = 1
}
udp_recv_channel {
#mcast_join = 239.2.11.71 don’t need to provide multicast address if using unicast
port = 8649
#retry_bind = true
}
Step 4: Create rrd directory, change permissions
Step 5: Copy the init script && binary to corresponding directory
Step 6: Start gmetad and gmond service
3. Install and configure gmond on client node
Put Ganglia on the compute nodes by just copying a few files. This is something you can add to a post install script.
Step 0: Create a file with all your host names.
Step 1: Change paths of libraries and run ganglia install script.
#!/bin/sh
for i in cat /home/gpadmin/yum_install/hosts_nomaster; do
scp /usr/sbin/gmond $i:/usr/sbin/gmond
ssh $i mkdir -p /etc/ganglia/
scp /etc/ganglia/gmond.conf $i:/etc/ganglia/
scp /etc/init.d/gmond $i:/etc/init.d/
scp /usr/local/lib64/libganglia-3.5.0.so.0 $i:/usr/local/lib64/
scp /usr/lib64/libexpat.so.0 $i:/usr/lib64/
scp /usr/local/lib/libconfuse.a $i:/usr/local/lib/
scp /usr/lib64/libapr-1.so.0 $i:/usr/lib64/
scp -r /usr/local/lib64/ganglia/ $i:/usr/local/lib64/ganglia/
ssh $i service gmond start
done
4. Install web front-end on server node
Step 0: Install prerequisites
Step 1: Install ganglia-web binary
Step 2: Configure rrdtool path
$conf[‘rrdtool’] = “/usr/lib64/rrdtool/bin/rrdtool”;
Step 3: Visit ganglia web interface through “http://server-ip/ganglia“
1. 首先, 我选择eclipse CDT作为开发工具,很简单, 在Help->Install New Software中输入一下网址安装插件即可
http://download.eclipse.org/tools/cdt/releases/helios
2. 下载postgres源码,配置、编译、安装
Step 2.1 在终端对PostgreSQL进行配置将目录切换到PostgreSQL源码的根目录,执行如下命令:
cd postgresql-9.2.2
./configure –prefix=$HOME/project –enable-depend –enable-cassert –enable-debug
其中–prefix指定PostgreSQL要安装的目录 (这个目录可以任意指定,但是建议使用绝对路径,这样在后续开发过程中不会出现因路径问题而产生的一系列莫名其妙的问题) –enable-depend、 –enable-cassert及 –enable-debug
Step 2.2 编译PostgreSQL
打开Eclipse将PostgreSQL源码导入Eclipse的工作目录,选择File–>import,选择Existing Code as Makefile Project, 然后点击Next,在下面的图示中选择PostgreSQL源码所在的目录,并为工程文件起一个项目名,并选择编译器
由于PostgreSQL是使用C编写的,所以也要把C++勾掉,只保留C,然后点击Finish,等待工程导入完毕,这里需要注意的是只有当工程完全导入之后才可以执行下面的操作,否可可能出现错误,(可以通过Eclipse右下角查看当前导入进度)。当工程完全导入之后没有出现错误,则表明PostgreSQL编译成功
Step 2.3 安装PostgreSQL
在导入的工程上右键选择Make Targets 然后选择Create,在Make Target选项卡中双击install进行安装,Eclipse控制台中出现“Postgres Installation Complete” 表明PostgreSQL安装成功。
3. 初始化Postgres
Step 3.1 此时的PostgreSQL还不能真正使用,还需要进行初始化,在终端中执行如下操作:
export PATH=$HOME/postgresql-9.2.2/bin:$PATH
export PGDATA=DemoDir
initdb
Step 3.2 在Eclipse中项目上右键选择Run As–>Run Configurations,双击C/C++ Application,在Main选项卡中点击Search Project选择Postgres点击Apply。然后再切换到Arguments选项卡,输入参数:-D DemoDir(即上面命令中PGDATA指定的路径)。点击Run,如果看到如下信息表示安装成功。
LOG: database system is ready to accept connections
LOG: autovacuum launcher started
4. 初始Postgres
在终端输入:
createdb DemoDB
psql -l
psql DemoDB
5. 在Eclipse中调试PostgreSQL源代码
如果要调试PostgreSQL源码,首先保证安装了gdb,之后在工程上右键,选择Debug As–>Local C/C++ Application,在弹出的窗口中选择postgres,点击OK, 这时我们就可以通过Eclipse调试PostgreSQL源码了
原文地址 http://my.oschina.net/lichhao/blog/104943
SpringMVC完成初始化流程之后,就进入Servlet标准生命周期的第二个阶段,即“service”阶段。在“service”阶段中,每一次Http请求到来,容器都会启动一个请求线程,通过service()方法,委派到doGet()或者doPost()这些方法,完成Http请求的处理。
在初始化流程中,SpringMVC巧妙的运用依赖注入读取参数,并最终建立一个与容器上下文相关联的Spring子上下文。这个子上下文,就像Struts2中xwork容器一样,为接下来的Http处理流程中各种编程元素提供了容身之所。如果说将Spring上下文关联到Servlet容器中,是SpringMVC框架的第一个亮点,那么在请求转发流程中,SpringMVC对各种处理环节编程元素的抽象,就是另外一个独具匠心的亮点。
Struts2采取的是一种完全和Web容器隔离和解耦的事件机制。诸如Action对象、Result对象、Interceptor对象,这些都是完全脱离Servlet容器的编程元素。Struts2将数据流和事件处理完全剥离开来,从Http请求中读取数据后,下面的事件处理流程就只依赖于这些数据,而完全不知道有Web环境的存在。
反观SpringMVC,无论HandlerMapping对象、HandlerAdapter对象还是View对象,这些核心的接口所定义的方法中,HttpServletRequest和HttpServletResponse对象都是直接作为方法的参数出现的。这也就意味着,框架的设计者,直接将SpringMVC框架和容器绑定到了一起。或者说,整个SpringMVC框架,都是依托着Servlet容器元素来设计的。下面就来看一下,源码中是如何体现这一点的。
1.请求转发的入口
就像任何一个注册在容器中的Servlet一样,DispatcherServlet也是通过自己的service()方法来接收和转发Http请求到具体的doGet()或doPost()这些方法的。以一次典型的GET请求为例,经过HttpServlet基类中service()方法的委派,请求会被转发到doGet()方法中。doGet()方法,在DispatcherServlet的父类FrameworkServlet类中被覆写。
[java]
@Override
protected final void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
[/java]
可以看到,这里只是简单的转发到processRequest()这个方法。
[java]
protected final void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
long startTime = System.currentTimeMillis();
Throwable failureCause = null;
// Expose current LocaleResolver and request as LocaleContext.
LocaleContext previousLocaleContext = LocaleContextHolder.getLocaleContext();
LocaleContextHolder.setLocaleContext(buildLocaleContext(request), this.threadContextInheritable);
// Expose current RequestAttributes to current thread.
RequestAttributes previousRequestAttributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes requestAttributes = null;
if (previousRequestAttributes == null || previousRequestAttributes.getClass().equals(ServletRequestAttributes.class)) {
requestAttributes = new ServletRequestAttributes(request);
RequestContextHolder.setRequestAttributes(requestAttributes, this.threadContextInheritable);
}
if (logger.isTraceEnabled()) {
logger.trace("Bound request context to thread: " + request);
}
try {
doService(request, response);
}
catch (ServletException ex) {
failureCause = ex;
throw ex;
}
catch (IOException ex) {
failureCause = ex;
throw ex;
}
catch (Throwable ex) {
failureCause = ex;
throw new NestedServletException("Request processing failed", ex);
}
finally {
// Clear request attributes and reset thread-bound context.
LocaleContextHolder.setLocaleContext(previousLocaleContext, this.threadContextInheritable);
if (requestAttributes != null) {
RequestContextHolder.setRequestAttributes(previousRequestAttributes, this.threadContextInheritable);
requestAttributes.requestCompleted();
}
if (logger.isTraceEnabled()) {
logger.trace("Cleared thread-bound request context: " + request);
}
if (logger.isDebugEnabled()) {
if (failureCause != null) {
this.logger.debug("Could not complete request", failureCause);
}
else {
this.logger.debug("Successfully completed request");
}
}
if (this.publishEvents) {
// Whether or not we succeeded, publish an event.
long processingTime = System.currentTimeMillis() - startTime;
this.webApplicationContext.publishEvent(
new ServletRequestHandledEvent(this,
request.getRequestURI(), request.getRemoteAddr(),
request.getMethod(), getServletConfig().getServletName(),
WebUtils.getSessionId(request), getUsernameForRequest(request),
processingTime, failureCause));
}
}
}[/java]
代码有点长,理解的要点是以doService()方法为区隔,前一部分是将当前请求的Locale对象和属性,分别设置到LocaleContextHolder和RequestContextHolder这两个抽象类中的ThreadLocal对象中,也就是分别将这两个东西和请求线程做了绑定。在doService()处理结束后,再恢复回请求前的LocaleContextHolder和RequestContextHolder,也即解除线程绑定。每次请求处理结束后,容器上下文都发布了一个ServletRequestHandledEvent事件,你可以注册监听器来监听该事件。
可以看到,processRequest()方法只是做了一些线程安全的隔离,真正的请求处理,发生在doService()方法中。点开FrameworkServlet类中的doService()方法。
[java]
protected abstract void doService(HttpServletRequest request, HttpServletResponse response)
throws Exception;
[/java]
又是一个抽象方法,这也是SpringMVC类设计中的惯用伎俩:父类抽象处理流程,子类给予具体的实现。真正的实现是在DispatcherServlet类中。
让我们接着看DispatcherServlet类中实现的doService()方法。
[java]
@Override
protected void doService(HttpServletRequest request, HttpServletResponse response) throws Exception {
if (logger.isDebugEnabled()) {
String requestUri = urlPathHelper.getRequestUri(request);
logger.debug("DispatcherServlet with name ‘" + getServletName() + "’ processing " + request.getMethod() +
" request for [" + requestUri + "]");
}
// Keep a snapshot of the request attributes in case of an include,
// to be able to restore the original attributes after the include.
Map<String, Object> attributesSnapshot = null;
if (WebUtils.isIncludeRequest(request)) {
logger.debug("Taking snapshot of request attributes before include");
attributesSnapshot = new HashMap<String, Object>();
Enumeration<?> attrNames = request.getAttributeNames();
while (attrNames.hasMoreElements()) {
String attrName = (String) attrNames.nextElement();
if (this.cleanupAfterInclude || attrName.startsWith("org.springframework.web.servlet")) {
attributesSnapshot.put(attrName, request.getAttribute(attrName));
}
}
}
// Make framework objects available to handlers and view objects.
request.setAttribute(WEB_APPLICATION_CONTEXT_ATTRIBUTE, getWebApplicationContext());
request.setAttribute(LOCALE_RESOLVER_ATTRIBUTE, this.localeResolver);
request.setAttribute(THEME_RESOLVER_ATTRIBUTE, this.themeResolver);
request.setAttribute(THEME_SOURCE_ATTRIBUTE, getThemeSource());
FlashMap inputFlashMap = this.flashMapManager.retrieveAndUpdate(request, response);
if (inputFlashMap != null) {
request.setAttribute(INPUT_FLASH_MAP_ATTRIBUTE, Collections.unmodifiableMap(inputFlashMap));
}
request.setAttribute(OUTPUT_FLASH_MAP_ATTRIBUTE, new FlashMap());
request.setAttribute(FLASH_MAP_MANAGER_ATTRIBUTE, this.flashMapManager);
try {
doDispatch(request, response);
}
finally {
// Restore the original attribute snapshot, in case of an include.
if (attributesSnapshot != null) {
restoreAttributesAfterInclude(request, attributesSnapshot);
}
}
}[/java]
几个requet.setAttribute()方法的调用,将前面在初始化流程中实例化的对象设置到http请求的属性中,供下一步处理使用,其中有容器的上下文对象、本地化解析器等SpringMVC特有的编程元素。不同于Struts2中的ValueStack,SpringMVC的数据并没有从HttpServletRequest对象中抽离出来再存进另外一个编程元素,这也跟SpringMVC的设计思想有关。因为从一开始,SpringMVC的设计者就认为,不应该将请求处理过程和Web容器完全隔离。
所以,你可以看到,真正发生请求转发的方法doDispatch()中,它的参数是HttpServletRequest和HttpServletResponse对象。这给我们传递的意思也很明确,从request中能获取到一切请求的数据,从response中,我们又可以往服务器端输出任何响应,Http请求的处理,就应该围绕这两个对象来设计。我们不妨可以将SpringMVC这种设计方案,是从Struts2的过度设计中吸取教训,而向Servlet编程的一种回归和简化。
2.请求转发的抽象描述
接下来让我们看看doDispatch()这个整个请求转发流程中最核心的方法。DispatcherServlet所接收的Http请求,经过层层转发,最终都是汇总到这个方法中来进行最后的请求分发和处理。doDispatch()这个方法的内容,就是SpringMVC整个框架的精华所在。它通过高度抽象的接口,描述出了一个MVC(Model-View-Controller)设计模式的实现方案。Model、View、Controller三种层次的编程元素,在SpringMVC中都有大量的实现类,各种处理细节也是千差万别。但是,它们最后都是由,也都能由doDispatch()方法来统一描述,这就是接口和抽象的威力,万变不离其宗。
先来看一下doDispatch()方法的庐山真面目。
[java]
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
int interceptorIndex = -1;
try {
ModelAndView mv;
boolean errorView = false;
try {
processedRequest = checkMultipart(request);
// Determine handler for the current request.
mappedHandler = getHandler(processedRequest, false);
if (mappedHandler == null || mappedHandler.getHandler() == null) {
noHandlerFound(processedRequest, response);
return;
}
// Determine handler adapter for the current request.
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Process last-modified header, if supported by the handler.
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (logger.isDebugEnabled()) {
String requestUri = urlPathHelper.getRequestUri(request);
logger.debug("Last-Modified value for [" + requestUri + "] is: " + lastModified);
}
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
}
// Apply preHandle methods of registered interceptors.
HandlerInterceptor[] interceptors = mappedHandler.getInterceptors();
if (interceptors != null) {
for (int i = 0; i < interceptors.length; i++) {
HandlerInterceptor interceptor = interceptors[i];
if (!interceptor.preHandle(processedRequest, response, mappedHandler.getHandler())) {
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, null);
return;
}
interceptorIndex = i;
}
}
// Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
// Do we need view name translation?
if (mv != null && !mv.hasView()) {
mv.setViewName(getDefaultViewName(request));
}
// Apply postHandle methods of registered interceptors.
if (interceptors != null) {
for (int i = interceptors.length - 1; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
interceptor.postHandle(processedRequest, response, mappedHandler.getHandler(), mv);
}
}
}
catch (ModelAndViewDefiningException ex) {
logger.debug("ModelAndViewDefiningException encountered", ex);
mv = ex.getModelAndView();
}
catch (Exception ex) {
Object handler = (mappedHandler != null ? mappedHandler.getHandler() : null);
mv = processHandlerException(processedRequest, response, handler, ex);
errorView = (mv != null);
}
// Did the handler return a view to render?
if (mv != null && !mv.wasCleared()) {
render(mv, processedRequest, response);
if (errorView) {
WebUtils.clearErrorRequestAttributes(request);
}
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Null ModelAndView returned to DispatcherServlet with name '" + getServletName() +
"': assuming HandlerAdapter completed request handling");
}
}
// Trigger after-completion for successful outcome.
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, null);
}
catch (Exception ex) {
// Trigger after-completion for thrown exception.
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, ex);
throw ex;
}
catch (Error err) {
ServletException ex = new NestedServletException("Handler processing failed", err);
// Trigger after-completion for thrown exception.
triggerAfterCompletion(mappedHandler, interceptorIndex, processedRequest, response, ex);
throw ex;
}
finally {
// Clean up any resources used by a multipart request.
if (processedRequest != request) {
cleanupMultipart(processedRequest);
}
}
}[/java]
真是千呼万唤始出来,犹抱琵琶半遮面。我们在第一篇《SpringMVC源码剖析(一)- 从抽象和接口说起》中所描述的各种编程元素,依次出现在该方法中。HandlerMapping、HandlerAdapter、View这些接口的设计,我们在第一篇中已经讲过。现在我们来重点关注一下HandlerExecutionChain这个对象。
从上面的代码中,很明显可以看出一条线索,整个方法是围绕着如何获取HandlerExecutionChain对象,执行HandlerExecutionChain对象得到相应的视图对象,再对视图进行渲染这条主线来展开的。HandlerExecutionChain对象显得异常重要。
因为Http请求要进入SpringMVC的处理体系,必须由HandlerMapping接口的实现类映射Http请求,得到一个封装后的HandlerExecutionChain对象。再由HandlerAdapter接口的实现类来处理这个HandlerExecutionChain对象所包装的处理对象,来得到最后渲染的视图对象。
视图对象是用ModelAndView对象来描述的,名字已经非常直白,就是数据和视图,其中的数据,由HttpServletRequest的属性得到,视图就是由HandlerExecutionChain封装的处理对象处理后得到。当然HandlerExecutionChain中的拦截器列表HandlerInterceptor,会在处理过程的前后依次被调用,为处理过程留下充足的扩展点。
所有的SpringMVC框架元素,都是围绕着HandlerExecutionChain这个执行链来发挥效用。我们来看看,HandlerExecutionChain类的代码。
[java]
package org.springframework.web.servlet;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.springframework.util.CollectionUtils;
public class HandlerExecutionChain {
private final Object handler;
private HandlerInterceptor[] interceptors;
private List<HandlerInterceptor> interceptorList;
public HandlerExecutionChain(Object handler) {
this(handler, null);
}
public HandlerExecutionChain(Object handler, HandlerInterceptor[] interceptors) {
if (handler instanceof HandlerExecutionChain) {
HandlerExecutionChain originalChain = (HandlerExecutionChain) handler;
this.handler = originalChain.getHandler();
this.interceptorList = new ArrayList<HandlerInterceptor>();
CollectionUtils.mergeArrayIntoCollection(originalChain.getInterceptors(), this.interceptorList);
CollectionUtils.mergeArrayIntoCollection(interceptors, this.interceptorList);
}
else {
this.handler = handler;
this.interceptors = interceptors;
}
}
public Object getHandler() {
return this.handler;
}
public void addInterceptor(HandlerInterceptor interceptor) {
initInterceptorList();
this.interceptorList.add(interceptor);
}
public void addInterceptors(HandlerInterceptor[] interceptors) {
if (interceptors != null) {
initInterceptorList();
this.interceptorList.addAll(Arrays.asList(interceptors));
}
}
private void initInterceptorList() {
if (this.interceptorList == null) {
this.interceptorList = new ArrayList<HandlerInterceptor>();
}
if (this.interceptors != null) {
this.interceptorList.addAll(Arrays.asList(this.interceptors));
this.interceptors = null;
}
}
public HandlerInterceptor[] getInterceptors() {
if (this.interceptors == null && this.interceptorList != null) {
this.interceptors = this.interceptorList.toArray(new HandlerInterceptor[this.interceptorList.size()]);
}
return this.interceptors;
}
@Override
public String toString() {
if (this.handler == null) {
return "HandlerExecutionChain with no handler";
}
StringBuilder sb = new StringBuilder();
sb.append("HandlerExecutionChain with handler [").append(this.handler).append("]");
if (!CollectionUtils.isEmpty(this.interceptorList)) {
sb.append(" and ").append(this.interceptorList.size()).append(" interceptor");
if (this.interceptorList.size() > 1) {
sb.append("s");
}
}
return sb.toString();
}
}[/java]
一个拦截器列表,一个执行对象,这个类的内容十分的简单,它蕴含的设计思想,却十分的丰富。
1.拦截器组成的列表,在执行对象被调用的前后,会依次执行。这里可以看成是一个的AOP环绕通知,拦截器可以对处理对象随心所欲的进行处理和增强。这里明显是吸收了Struts2中拦截器的设计思想。这种AOP环绕式的扩展点设计,也几乎成为所有框架必备的内容。
2.实际的处理对象,即handler对象,是由Object对象来引用的。
[java]
private final Object handler;[/java]
之所以要用一个java世界最基础的Object对象引用来引用这个handler对象,是因为连特定的接口也不希望绑定在这个handler对象上,从而使handler对象具有最大程度的选择性和灵活性。
我们常说,一个框架最高层次的抽象是接口,但是这里SpringMVC更进了一步。在最后的处理对象上面,SpringMVC没有对它做任何的限制,只要是java世界中的对象,都可以用来作为最后的处理对象,来生成视图。极端一点来说,你甚至可以将另外一个MVC框架集成到SpringMVC中来,也就是为什么SpringMVC官方文档中,居然还有集成其他表现层框架的内容。这一点,在所有表现层框架中,是独领风骚,冠绝群雄的。
3.结语
SpringMVC的成功,源于它对开闭原则的运用和遵守。也正因此,才使得整个框架具有如此强大的描述和扩展能力。这也许和SpringMVC出现和兴起的时间有关,正是经历了Struts1到Struts2这些Web开发领域MVC框架的更新换代,它的设计者才能站在前人的肩膀上。知道了如何将事情做的糟糕之后,你或许才知道如何将事情做得好。
希望在这个系列里面分享的SpringMVC源码阅读经验,能帮助读者们从更高的层次来审视SpringMVC框架的设计,也希望这里所描述的一些基本设计思想,能在你更深入的了解SpringMVC的细节时,对你有帮助。哲学才是唯一的、最终的武器,在一个框架的设计上,尤其是如此。经常地体会一个框架设计者的设计思想,对你更好的使用它,是有莫大的益处的。
原文地址 http://my.oschina.net/lichhao/blog/102315
在我们第一次学Servlet编程,学java web的时候,还没有那么多框架。我们开发一个简单的功能要做的事情很简单,就是继承HttpServlet,根据需要重写一下doGet,doPost方法,跳转到我们定义好的jsp页面。Servlet类编写完之后在web.xml里注册这个Servlet类。
除此之外,没有其他了。我们启动web服务器,在浏览器中输入地址,就可以看到浏览器上输出我们写好的页面。为了更好的理解上面这个过程,你需要学习关于Servlet生命周期的三个阶段,就是所谓的“init-service-destroy”。
以上的知识,我觉得对于你理解SpringMVC的设计思想,已经足够了。SpringMVC当然可以称得上是一个复杂的框架,但是同时它又遵循Servlet世界里最简单的法则,那就是“init-service-destroy”。我们要分析SpringMVC的初始化流程,其实就是分析DispatcherServlet类的init()方法,让我们带着这种单纯的观点,打开DispatcherServlet的源码一窥究竟吧。
1.
用Eclipse IDE打开DispatcherServlet类的源码,ctrl+T看一下。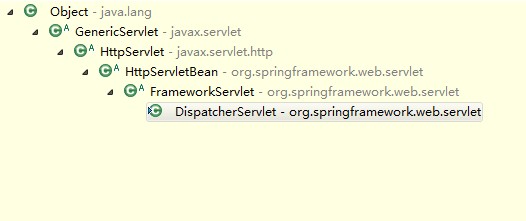
DispatcherServlet类的初始化入口方法init()定义在HttpServletBean这个父类中,HttpServletBean类作为一个直接继承于HttpServlet类的类,覆写了HttpServlet类的init()方法,实现了自己的初始化行为。
[java]
@Override
public final void init() throws ServletException {
if (logger.isDebugEnabled()) {
logger.debug("Initializing servlet ‘" + getServletName() + "’");
}
// Set bean properties from init parameters.
try {
PropertyValues pvs = new ServletConfigPropertyValues(getServletConfig(), this.requiredProperties);
BeanWrapper bw = PropertyAccessorFactory.forBeanPropertyAccess(this);
ResourceLoader resourceLoader = new ServletContextResourceLoader(getServletContext());
bw.registerCustomEditor(Resource.class, new ResourceEditor(resourceLoader, this.environment));
initBeanWrapper(bw);
bw.setPropertyValues(pvs, true);
}
catch (BeansException ex) {
logger.error("Failed to set bean<span></span> properties on servlet '" + getServletName() + "'", ex);
throw ex;
}
// Let subclasses do whatever initialization they like.
initServletBean();
if (logger.isDebugEnabled()) {
logger.debug("Servlet '" + getServletName() + "' configured successfully");
}
}
[/java]
这里的initServletBean()方法在HttpServletBean类中是一个没有任何实现的空方法,它的目的就是留待子类实现自己的初始化逻辑,也就是我们常说的模板方法设计模式。SpringMVC在此生动的运用了这个模式,init()方法就是模版方法模式中的模板方法,SpringMVC真正的初始化过程,由子类FrameworkServlet中覆写的initServletBean()方法触发。
再看一下init()方法内被try,catch块包裹的代码,里面涉及到BeanWrapper,PropertyValues,ResourceEditor这些Spring内部非常底层的类。要深究具体代码实现上面的细节,需要对Spring框架源码具有相当深入的了解。我们这里先避繁就简,从代码效果和设计思想上面来分析这段try,catch块内的代码所做的事情:
注册一个字符串到资源文件的编辑器,让Servlet下面的
将web.xml中在DispatcherServlet这个Servlet下面的
这两点,我想通过下面一个例子来说明一下。
我在web.xml中注册的DispatcherServlet配置如下:
[java]
<!– springMVC配置开始 –>
<servlet>
<servlet-name>appServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring/spring-servlet.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>appServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<!– springMVC配置结束 –>[/java]
可以看到,我注册了一个名为contextConfigLocation的
另外一个作用,就是将contextConfigLocation的值读取出来,然后通过setContextConfigLocation()方法设置到DispatcherServlet中,这个setContextConfigLocation()方法是在FrameworkServlet类中定义的,也就是上面继承类图中DispatcherServlet的直接父类。
我们在setContextConfigLocation()方法上面打上一个断点,启动web工程,可以看到下面的调试结果。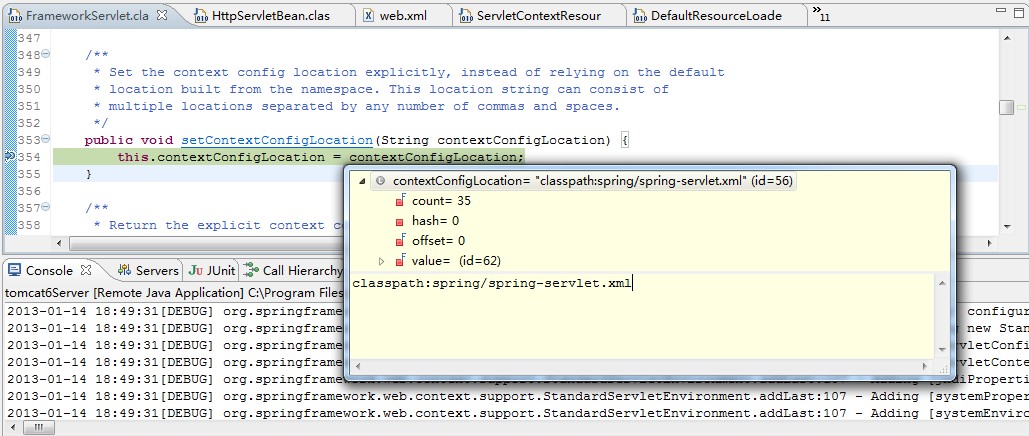
HttpServletBean类的作者是大名鼎鼎的Spring之父Rod Johnson。作为POJO编程哲学的大师,他在HttpServletBean这个类的设计中,运用了依赖注入思想完成了
明白了HttpServletBean类的设计思想,我们也就知道可以如何从中获益。具体来说,我们继承HttpServletBean类(就像DispatcherServlet做的那样),在类中定义一个属性,为这个属性加上setter方法后,我们就可以在
注意,虽然SpringMVC本身为了后面初始化上下文的方便,使用了字符串来声明和设置contextConfigLocation参数,但是将其声明为Resource类型,同样能够成功获取。鼓励读者们自己继承HttpServletBean写一个测试用的Servlet类,并设置一个参数来调试一下,这样能够帮助你更好的理解获取配置参数的过程。
2.容器上下文的建立
上一篇文章中提到过,SpringMVC使用了Spring容器来容纳自己的配置元素,拥有自己的bean容器上下文。在SpringMVC初始化的过程中,非常关键的一步就是要建立起这个容器上下文,而这个建立上下文的过程,发生在FrameworkServlet类中,由上面init()方法中的initServletBean()方法触发。
[java]
@Override
protected final void initServletBean() throws ServletException {
getServletContext().log("Initializing Spring FrameworkServlet ‘" + getServletName() + "’");
if (this.logger.isInfoEnabled()) {
this.logger.info("FrameworkServlet ‘" + getServletName() + "’: initialization started");
}
long startTime = System.currentTimeMillis();
try {
this.webApplicationContext = initWebApplicationContext();
initFrameworkServlet();
}
catch (ServletException ex) {
this.logger.error("Context initialization failed", ex);
throw ex;
}
catch (RuntimeException ex) {
this.logger.error("Context initialization failed", ex);
throw ex;
}
if (this.logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
this.logger.info("FrameworkServlet '" + getServletName() + "': initialization completed in " +
elapsedTime + " ms");
}
}[/java]
initFrameworkServlet()方法是一个没有任何实现的空方法,除去一些样板式的代码,那么这个initServletBean()方法所做的事情已经非常明白:
[java]
this.webApplicationContext = initWebApplicationContext();[/java]
这一句简单直白的代码,道破了FrameworkServlet这个类,在SpringMVC类体系中的设计目的,它是 用来抽离出建立 WebApplicationContext 上下文这个过程的。
initWebApplicationContext()方法,封装了建立Spring容器上下文的整个过程,方法内的逻辑如下:
获取由ContextLoaderListener初始化并注册在ServletContext中的根上下文,记为rootContext
如果webApplicationContext已经不为空,表示这个Servlet类是通过编程式注册到容器中的(Servlet 3.0+中的ServletContext.addServlet() ),上下文也由编程式传入。若这个传入的上下文还没被初始化,将rootContext上下文设置为它的父上下文,然后将其初始化,否则直接使用。
通过wac变量的引用是否为null,判断第2步中是否已经完成上下文的设置(即上下文是否已经用编程式方式传入),如果wac==null成立,说明该Servlet不是由编程式注册到容器中的。此时以contextAttribute属性的值为键,在ServletContext中查找上下文,查找得到,说明上下文已经以别的方式初始化并注册在contextAttribute下,直接使用。
检查wac变量的引用是否为null,如果wac==null成立,说明2、3两步中的上下文初始化策略都没成功,此时调用createWebApplicationContext(rootContext),建立一个全新的以rootContext为父上下文的上下文,作为SpringMVC配置元素的容器上下文。大多数情况下我们所使用的上下文,就是这个新建的上下文。
以上三种初始化上下文的策略,都会回调onRefresh(ApplicationContext context)方法(回调的方式根据不同策略有不同),onRefresh方法在DispatcherServlet类中被覆写,以上面得到的上下文为依托,完成SpringMVC中默认实现类的初始化。
最后,将这个上下文发布到ServletContext中,也就是将上下文以一个和Servlet类在web.xml中注册名字有关的值为键,设置为ServletContext的一个属性。你可以通过改变publishContext的值来决定是否发布到ServletContext中,默认为true。
以上面6点跟踪FrameworkServlet类中的代码,可以比较清晰的了解到整个容器上下文的建立过程,也就能够领会到FrameworkServlet类的设计目的,它是用来建立一个和Servlet关联的Spring容器上下文,并将其注册到ServletContext中的。跳脱开SpringMVC体系,我们也能通过继承FrameworkServlet类,得到与Spring容器整合的好处,FrameworkServlet和HttpServletBean一样,是一个可以独立使用的类。整个SpringMVC设计中,处处体现开闭原则,这里显然也是其中一点。
3.初始化SpringMVC默认实现类
初始化流程在FrameworkServlet类中流转,建立了上下文后,通过onRefresh(ApplicationContext context)方法的回调,进入到DispatcherServlet类中。
[java]
@Override
protected void onRefresh(ApplicationContext context) {
initStrategies(context);
}[/java]
DispatcherServlet类覆写了父类FrameworkServlet中的onRefresh(ApplicationContext context)方法,提供了SpringMVC各种编程元素的初始化。当然这些编程元素,都是作为容器上下文中一个个bean而存在的。具体的初始化策略,在initStrategies()方法中封装。
[java]
protected void initStrategies(ApplicationContext context) {
initMultipartResolver(context);
initLocaleResolver(context);
initThemeResolver(context);
initHandlerMappings(context);
initHandlerAdapters(context);
initHandlerExceptionResolvers(context);
initRequestToViewNameTranslator(context);
initViewResolvers(context);
initFlashMapManager(context);
}[/java]
我们以其中initHandlerMappings(context)方法为例,分析一下这些SpringMVC编程元素的初始化策略,其他的方法,都是以类似的策略初始化的。
[java]
private void initHandlerMappings(ApplicationContext context) {
this.handlerMappings = null;
if (this.detectAllHandlerMappings) {
// Find all HandlerMappings in the ApplicationContext, including ancestor contexts.
Map<String, HandlerMapping> matchingBeans =
BeanFactoryUtils.beansOfTypeIncludingAncestors(context, HandlerMapping.class, true, false);
if (!matchingBeans.isEmpty()) {
this.handlerMappings = new ArrayList<HandlerMapping>(matchingBeans.values());
// We keep HandlerMappings in sorted order.
OrderComparator.sort(this.handlerMappings);
}
}
else {
try {
HandlerMapping hm = context.getBean(HANDLER_MAPPING_BEAN_NAME, HandlerMapping.class);
this.handlerMappings = Collections.singletonList(hm);
}
catch (NoSuchBeanDefinitionException ex) {
// Ignore, we'll add a default HandlerMapping later.
}
}
// Ensure we have at least one HandlerMapping, by registering
// a default HandlerMapping if no other mappings are found.
if (this.handlerMappings == null) {
this.handlerMappings = getDefaultStrategies(context, HandlerMapping.class);
if (logger.isDebugEnabled()) {
logger.debug("No HandlerMappings found in servlet '" + getServletName() + "': using default");
}
}
}[/java]
detectAllHandlerMappings变量默认为true,所以在初始化HandlerMapping接口默认实现类的时候,会把上下文中所有HandlerMapping类型的Bean都注册在handlerMappings这个List变量中。如果你手工将其设置为false,那么将尝试获取名为handlerMapping的Bean,新建一个只有一个元素的List,将其赋给handlerMappings。如果经过上面的过程,handlerMappings变量仍为空,那么说明你没有在上下文中提供自己HandlerMapping类型的Bean定义。此时,SpringMVC将采用默认初始化策略来初始化handlerMappings。
点进去getDefaultStrategies看一下。
[java]
@SuppressWarnings("unchecked")
protected <T> List<T> getDefaultStrategies(ApplicationContext context, Class<T> strategyInterface) {
String key = strategyInterface.getName();
String value = defaultStrategies.getProperty(key);
if (value != null) {
String[] classNames = StringUtils.commaDelimitedListToStringArray(value);
List<T> strategies = new ArrayList<T>(classNames.length);
for (String className : classNames) {
try {
Class<?> clazz = ClassUtils.forName(className, DispatcherServlet.class.getClassLoader());
Object strategy = createDefaultStrategy(context, clazz);
strategies.add((T) strategy);
}
catch (ClassNotFoundException ex) {
throw new BeanInitializationException(
"Could not find DispatcherServlet’s default strategy class [" + className +
"] for interface [" + key + "]", ex);
}
catch (LinkageError err) {
throw new BeanInitializationException(
"Error loading DispatcherServlet’s default strategy class [" + className +
"] for interface [" + key + "]: problem with class file or dependent class", err);
}
}
return strategies;
}
else {
return new LinkedList<T>();
}
}[/java]
它是一个范型的方法,承担所有SpringMVC编程元素的默认初始化策略。方法的内容比较直白,就是以传递类的名称为键,从defaultStrategies这个Properties变量中获取实现类,然后反射初始化。
需要说明一下的是defaultStrategies变量的初始化,它是在DispatcherServlet的静态初始化代码块中加载的。
[java]
private static final Properties defaultStrategies;
static {
// Load default strategy implementations from properties file.
// This is currently strictly internal and not meant to be customized
// by application developers.
try {
ClassPathResource resource = new ClassPathResource(DEFAULT_STRATEGIES_PATH, DispatcherServlet.class);
defaultStrategies = PropertiesLoaderUtils.loadProperties(resource);
}
catch (IOException ex) {
throw new IllegalStateException("Could not load ‘DispatcherServlet.properties’: " + ex.getMessage());
}
}[/java]
[java]
private static final String DEFAULT_STRATEGIES_PATH = "DispatcherServlet.properties";[/java]
这个DispatcherServlet.properties里面,以键值对的方式,记录了SpringMVC默认实现类,它在spring-webmvc-3.1.3.RELEASE.jar这个jar包内,在org.springframework.web.servlet包里面。
[java]
org.springframework.web.servlet.LocaleResolver=org.springframework.web.servlet.i18n.AcceptHeaderLocaleResolver
org.springframework.web.servlet.ThemeResolver=org.springframework.web.servlet.theme.FixedThemeResolver
org.springframework.web.servlet.HandlerMapping=org.springframework.web.servlet.handler.BeanNameUrlHandlerMapping,\
org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping
org.springframework.web.servlet.HandlerAdapter=org.springframework.web.servlet.mvc.HttpRequestHandlerAdapter,\
org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter,\
org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter
org.springframework.web.servlet.HandlerExceptionResolver=org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerExceptionResolver,\
org.springframework.web.servlet.mvc.annotation.ResponseStatusExceptionResolver,\
org.springframework.web.servlet.mvc.support.DefaultHandlerExceptionResolver
org.springframework.web.servlet.RequestToViewNameTranslator=org.springframework.web.servlet.view.DefaultRequestToViewNameTranslator
org.springframework.web.servlet.ViewResolver=org.springframework.web.servlet.view.InternalResourceViewResolver
org.springframework.web.servlet.FlashMapManager=org.springframework.web.servlet.support.SessionFlashMapManager[/java]
至此,我们分析完了initHandlerMappings(context)方法的执行过程,其他的初始化过程与这个方法非常类似。所有初始化方法执行完后,SpringMVC正式完成初始化,静静等待Web请求的到来。
4.总结
回顾整个SpringMVC的初始化流程,我们看到,通过HttpServletBean、FrameworkServlet、DispatcherServlet三个不同的类层次,SpringMVC的设计者将三种不同的职责分别抽象,运用模版方法设计模式分别固定在三个类层次中。其中HttpServletBean完成的是